OLAP
Online analytical processing (OLAP) is a system for performing multi-dimensional analysis at high speeds on large volumes of data. Typically, this data is from a data warehouse, data mart or some other centralized data store. OLAP is ideal for data mining, business intelligence and complex analytical calculations, as well as business reporting functions like financial analysis, budgeting and sales forecasting.
The core of most OLAP databases is the OLAP cube, which allows you to quickly query, report on and analyze multidimensional data. What’s a data dimension? It’s simply one element of a particular dataset. For example, sales figures might have several dimensions related to region, time of year, product models and more.
The OLAP cube extends the row-by-column format of a traditional relational database schema and adds layers for other data dimensions. For example, while the top layer of the cube might organize sales by region, data analysts can also “drill-down” into layers for sales by state/province, city and/or specific stores. This historical, aggregated data for OLAP is usually stored in a star schema or snowflake schema.
The following graphic shows the OLAP cube for sales data in multiple dimensions — by region, by quarter and by product: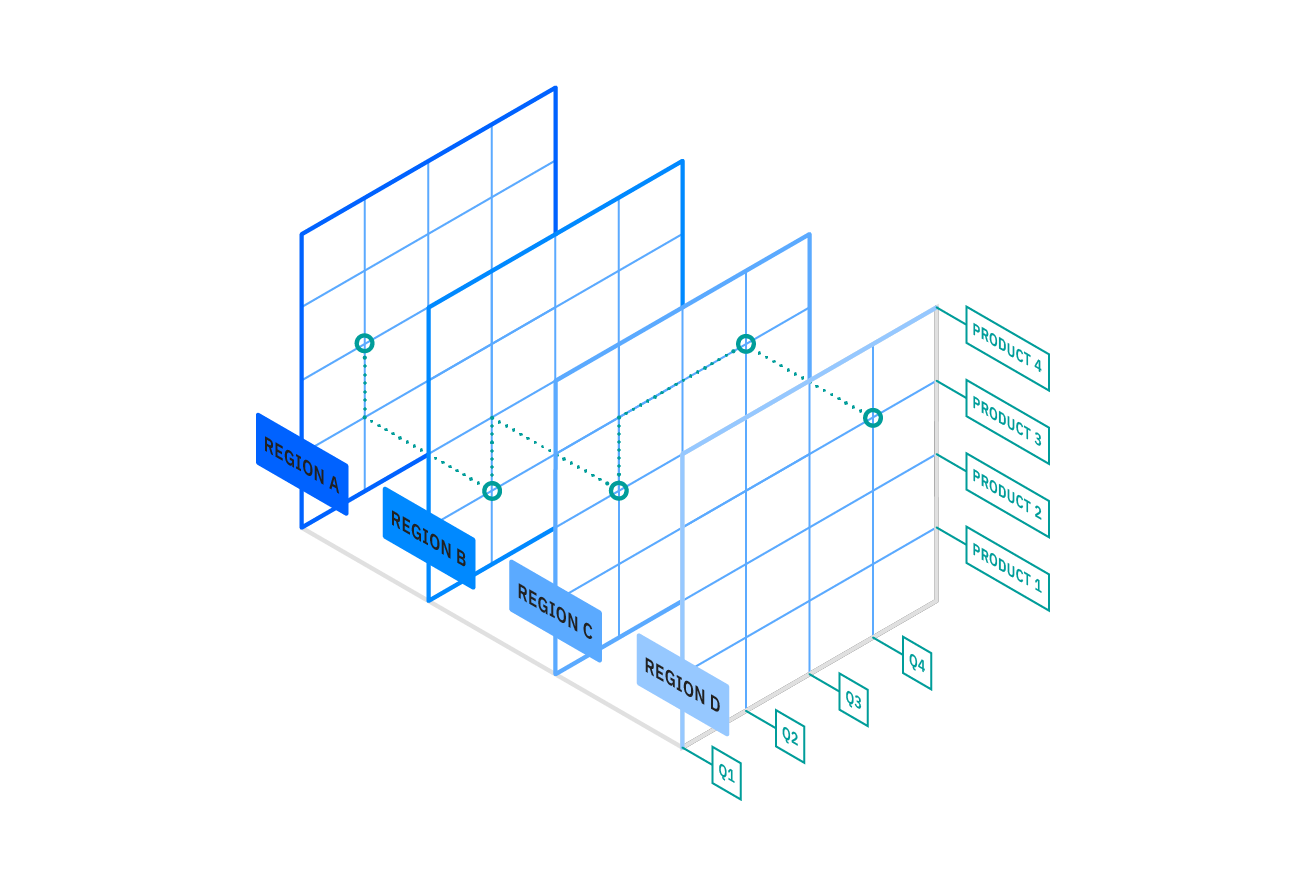
OLTP
Online transactional processing (OLTP) enables the real-time execution of large numbers of database transactions by large numbers of people, typically over the Internet. OLTP systems are behind many of our everyday transactions, from ATMs to in-store purchases to hotel reservations. OLTP can also drive non-financial transactions, including password changes and text messages.
OLTP systems use a relational database that can do the following:
- Process a large number of relatively simple transactions — usually insertions, updates and deletions to data.
- Enable multi-user access to the same data, while ensuring data integrity.
- Support very rapid processing, with response times measured in milliseconds.
- Provide indexed data sets for rapid searching, retrieval and querying.
- Be available 24/7/365, with constant incremental backups.
Many organizations use OLTP systems to provide data for OLAP. In other words, a combination of both OLTP and OLAP are essential in our data-driven world.
The main difference between OLAP and OLTP: Processing type
The main distinction between the two systems is in their names: analytical vs. transactional. Each system is optimized for that type of processing.
OLAP is optimized for conducting complex data analysis for smarter decision-making. OLAP systems are designed for use by data scientists, business analysts and knowledge workers, and they support business intelligence (BI), data mining and other decision support applications.
OLTP, on the other hand, is optimized for processing a massive number of transactions. OLTP systems are designed for use by frontline workers (e.g., cashiers, bank tellers, hotel desk clerks) or for customer self-service applications (e.g., online banking, e-commerce, travel reservations).
Other key differences between OLAP and OLTP
- Focus: OLAP systems allow you to extract data for complex analysis. To drive business decisions, the queries often involve large numbers of records. In contrast, OLTP systems are ideal for making simple updates, insertions and deletions in databases. The queries typically involve just one or a few records.
- Data source: An OLAP database has a multi-dimensional schema, so it can support complex queries of multiple data facts from current and historical data. Different OLTP databases can be the source of aggregated data for OLAP, and they may be organized as a data warehouse. OLTP, on the other hand, uses a traditional DBMS to accommodate a large volume of real-time transactions.
- Processing time: In OLAP, response times are orders of magnitude slower than OLTP. Workloads are read-intensive, involving enormous data sets. For OLTP transactions and responses, every millisecond counts. Workloads involve simple read and write operations via SQL (structured query language), requiring less time and less storage space.
- Availability: Since they don’t modify current data, OLAP systems can be backed up less frequently. However, OLTP systems modify data frequently, since this is the nature of transactional processing. They require frequent or concurrent backups to help maintain data integrity.